Introducing longrun-prd-runner: Why Long-Running Agent Work Needs a Control Plane
Why longrun-prd-runner matters: not as another coding agent, but as a control plane for governable, long-running execution.
The most important shift in agentic software is not that models can write code.
It is that they can now write enough code that coordination becomes the bottleneck.
A loud failure is annoying. A silent false positive that sends ten downstream tasks in the wrong direction is expensive.
That is the context for longrun-prd-runner.
I built it after running coding-agent workflows continuously for 24+ hours and realizing that the hard problem was no longer “can the model code?” It was “how do you manage long, multi-step execution safely?”
If you are only using agents for one-off edits, this may feel like overkill. If you are trying to move release-shaped work through a real codebase over hours or days, it is the missing layer.
Most of the conversation around coding agents still lives at the prompt layer. Can the model fix a bug? Can it scaffold a feature? Can it refactor a module, write a migration, or clean up a failing test? Those are still useful questions. They are just no longer the deepest ones.
The harder question is what happens when the work is not one task, but fifty. Or a hundred. Or two hundred. What happens when tasks depend on one another, validators need to pass before the next step can begin, reviews need to escalate when risk goes up, and the whole run stretches across hours or days instead of minutes.
That is where most agent demos quietly fall apart.
They show generation. They do not show governable execution.
And that is why longrun-prd-runner matters.
The bottleneck moves up a layer
Section titled “The bottleneck moves up a layer”The repo defines the problem with unusual clarity: real work often looks like 20 to 200 sequential tasks with dependencies, validation requirements, failures that need fixing, and long runtimes.
A single agent session can feel magical because the scope is local. The model gets a bounded prompt, edits a few files, and returns a plausible result. But once the same workflow becomes multi-stage, the failure modes change.
Now the questions are operational.
Did the task actually finish? Should the next task start? What proves completion? How many repairs are allowed before a human has to step in? What can run unattended and what requires an approval gate?
Think about something as ordinary as a release workflow. A PRD becomes a migration, a backfill, a test pass, a review pass, a docs update, and a rollout sequence. The problem is not whether a model can write each step. The problem is whether the system knows what must happen first, what proves completion, what can be retried, and when a human should stop the line.
This is not a prompting problem. It is an orchestration problem.
That distinction is what makes this repo more important than a typical agent demo. It is aimed at the layer above generation: the system that decides how generated work moves, stops, proves itself, and resumes.
From prompts to operational contracts
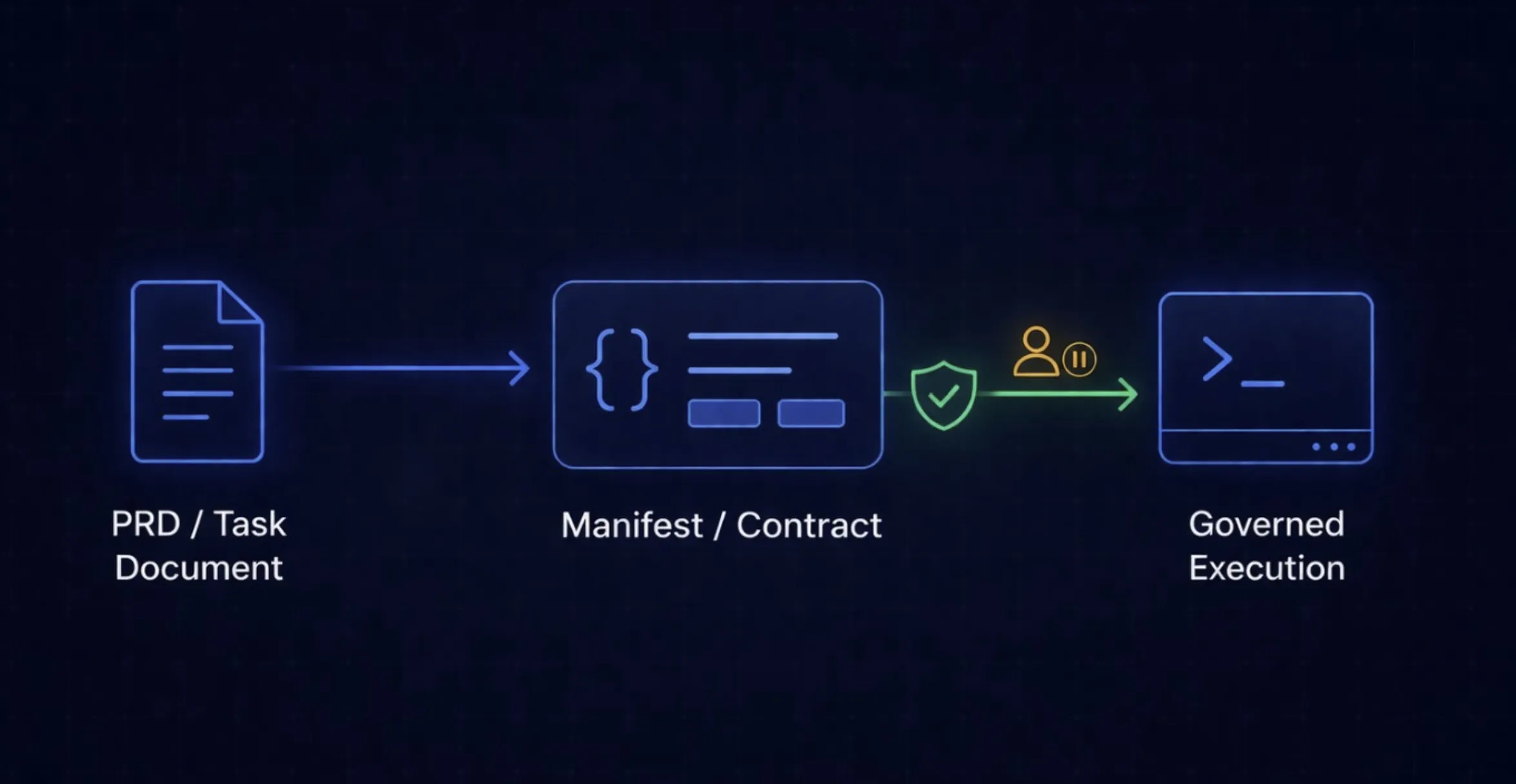
Section titled “From prompts to operational contracts”The cleanest idea in longrun-prd-runner is the shift from prompt-driven work to manifest-driven work.
The pipeline is explicit: PRD to manifest to long-running execution.
That middle artifact matters more than it first appears.
A prompt is ephemeral. A manifest is inspectable. A prompt is easy to improvise but hard to govern. A manifest can carry task structure, dependencies, validators, review policy, risk, and approval requirements. A prompt is a request. A manifest is an operational contract.
That is the difference between “try to do this feature” and “execute this ordered program of work, under these constraints, and do not advance unless the relevant checks pass.”
As long as prompts remain the main interface, teams will keep getting local intelligence without system reliability. Once the manifest becomes the interface, teams can inspect intent before execution, replay runs, resume from a failure point, and treat the workflow itself as software.
That is a much more durable abstraction.
What that contract looks like
Section titled “What that contract looks like”This is the remaining piece that matters for practicality: what does a manifest task actually look like?
The repo includes a tiny public example manifest. The actual file is JSON, but the shape is easier to read when simplified into a YAML-style excerpt:
scripts/toy/smoke_check.shreports/toy/smoke_check.json
X1-01That is the point.
The system is not merely told “write the smoke check.” It is told what artifact should exist, what validator proves completion, what review posture to apply, and what must already be done before the task can start.
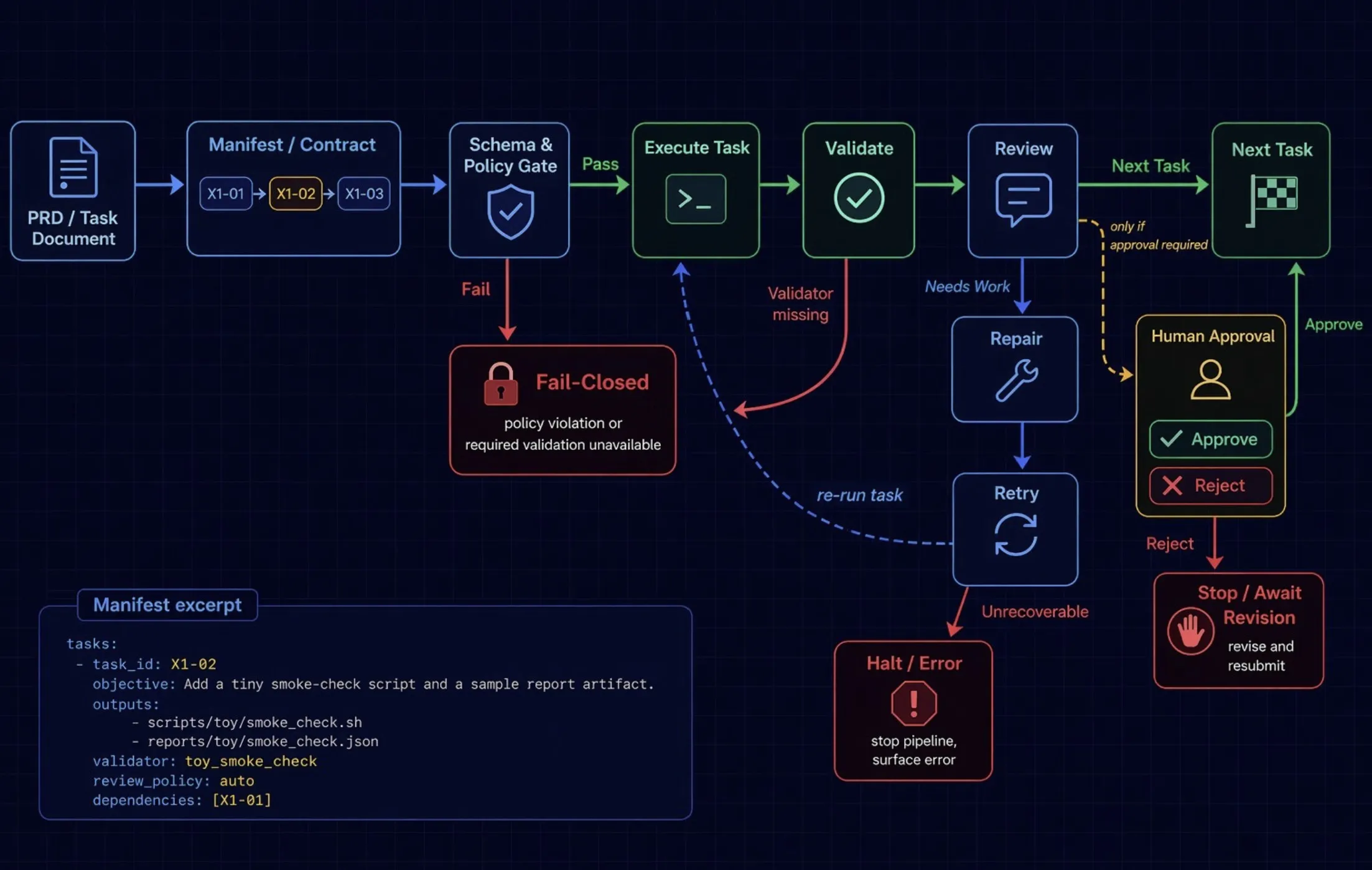
If you zoom back out, the runner’s architecture is just as explicit:
PRD -> generate manifest -> check schema + repo policy -> execute task -> validate -> review / remediate if needed -> continue or stop at a human gateThis is why the manifest matters so much. It turns a vague instruction into a runnable program of work.
Why this matters economically
Section titled “Why this matters economically”The value here is not only safety. It is leverage.
The README describes a system that uses cheaper models for low-risk tasks and escalates to stronger models when validation fails, reviews get riskier, or execution reaches critical paths. Runs are resumable. Retry and repair are bounded. Humans are pulled in at explicit gates instead of hovering over every step.
That design has an organizational payoff.
It means more validated work per engineer-hour. It means less senior attention spent babysitting prompts. It means less wasted motion from restarting long runs. It means fewer expensive cleanups after polished but incorrect output slips through.
That is engineering velocity. It is also capital efficiency.
As model output gets cheaper, the scarce resource is not generation. It is trustworthy throughput. The teams that win will not be the teams that can create the most agent motion. They will be the teams that can turn agent motion into validated progress.
Why the safety model is the product
Section titled “Why the safety model is the product”The architecture doc contains the most important line in the repo: Codex output alone is never treated as sufficient proof of correctness.
That is the right boundary.
The architecture makes three things the source of truth: validators for completion, repo policy for manifest safety, and human gates for governance decisions. Missing validators fail closed unless the user explicitly opts into sample mode. Manifest policy is checked before execution. Human approvals are explicit runtime gates, not vague intentions.
Those choices are not implementation details. They are the product.
A lot of agent tooling still behaves as if the main job is to maximize autonomous motion. But in real engineering systems, ungoverned motion is often worse than delay. A loud failure is recoverable. A silent false positive is where costs compound.
That is why fail-closed validation matters. That is why explicit policy checks matter. That is why human gates matter.
The goal is not to create an agent that always keeps going. The goal is to create a workflow that can keep going safely, and stop in the right places.
That is a much more serious ambition.
This is a control plane, not another agent
Section titled “This is a control plane, not another agent”longrun-prd-runner is best understood as a control plane around coding agents, not as another coding agent.
Models generate code. Control planes manage execution.
A control plane decides what the unit of work is. It decides how work is sequenced. It decides what evidence counts as completion. It decides what policy boundaries are non-negotiable. It decides when to retry, when to escalate, when to pause, and how to resume.
Every serious agent workflow eventually has to build this layer, whether or not it uses that name.
That is why this repo points at something larger than itself. It is not just a utility for one workflow. It is an example of where the stack is moving.
As code generation improves, the marginal value of one more clever prompt falls. The value of turning a large objective into a structured, resumable, validated execution system rises.
In other words: generation is becoming abundant. Reliable orchestration is becoming scarce.
This is also what the Multi-Threaded Operator thesis looks like at the tooling layer. The enduring advantage is not simply having more capable models. It is being able to direct many threads of machine execution without surrendering judgment, policy, or accountability.
Where I would start
Section titled “Where I would start”The README recommends the right posture for a first run: generate a manifest in plan-only mode, dry-run the queue, run a single task, and only consider unattended execution after validating the manifest, validators, and review policy.
That is how serious infrastructure should introduce itself.
Not with bravado. With constraints.
And in the agent era, constraints are often the clearest sign that a tool understands the problem it is trying to solve.
That is why I think longrun-prd-runner is worth paying attention to now.
Not because it makes coding agents look smarter. But because it makes long-running agent work more governable.